С ключевыми навыками разобрались. Теперь поговорим о том, как становятся data-инженерами в Т‑Банке. На практике в лагерь инженеров данных часто попадают специалисты из смежных областей. Например, такие:
- ETL-разработчик;
- ML-разработчик;
- Backend- или fullstack-разработчик.
Чтобы специалисты знали, в какую сторону развиваться, чтобы стать data-инженером, мы создали универсальную матрицу компетенций. По сути, это развитие методики универсальной карты компетенций ETL-разработчика, про которую рассказывала Галина Голованова.
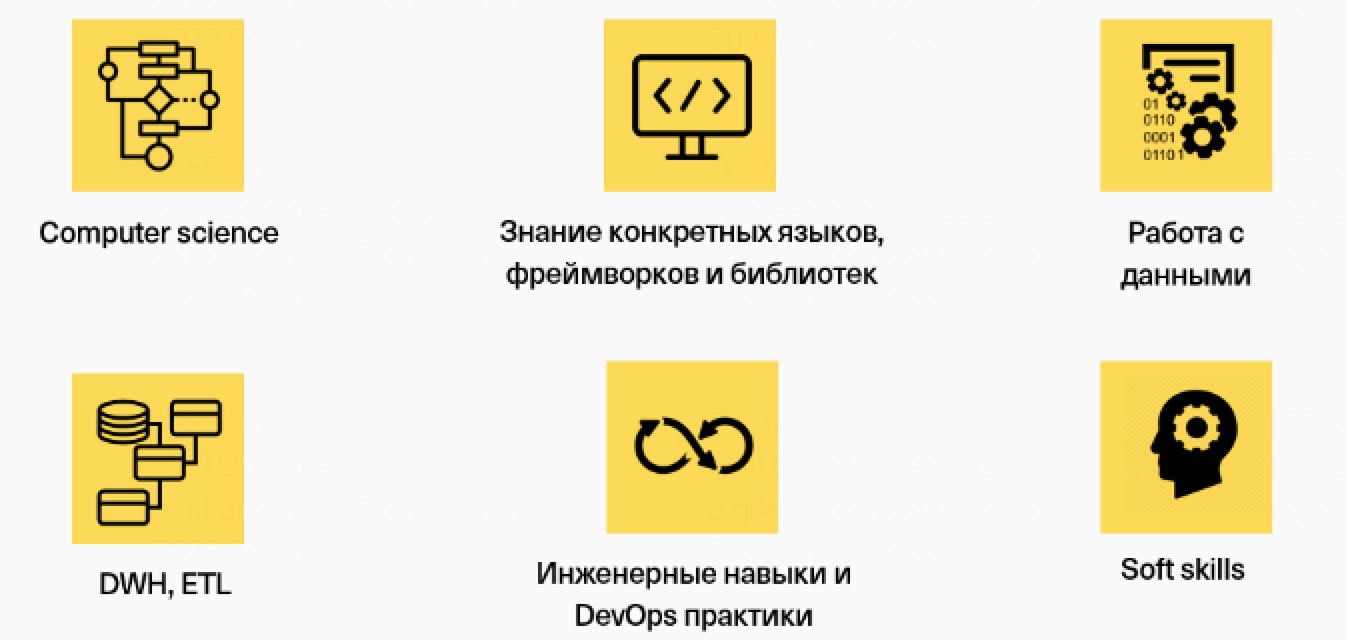
Матрица компетенций data-инженера — это детализированный перечень основных навыков, описанных выше. Матрица учитывает в первую очередь технологии, с которыми работают инженеры в компании. А универсальна она потому, что в ней есть альтернативные разделы для каждого навыка.
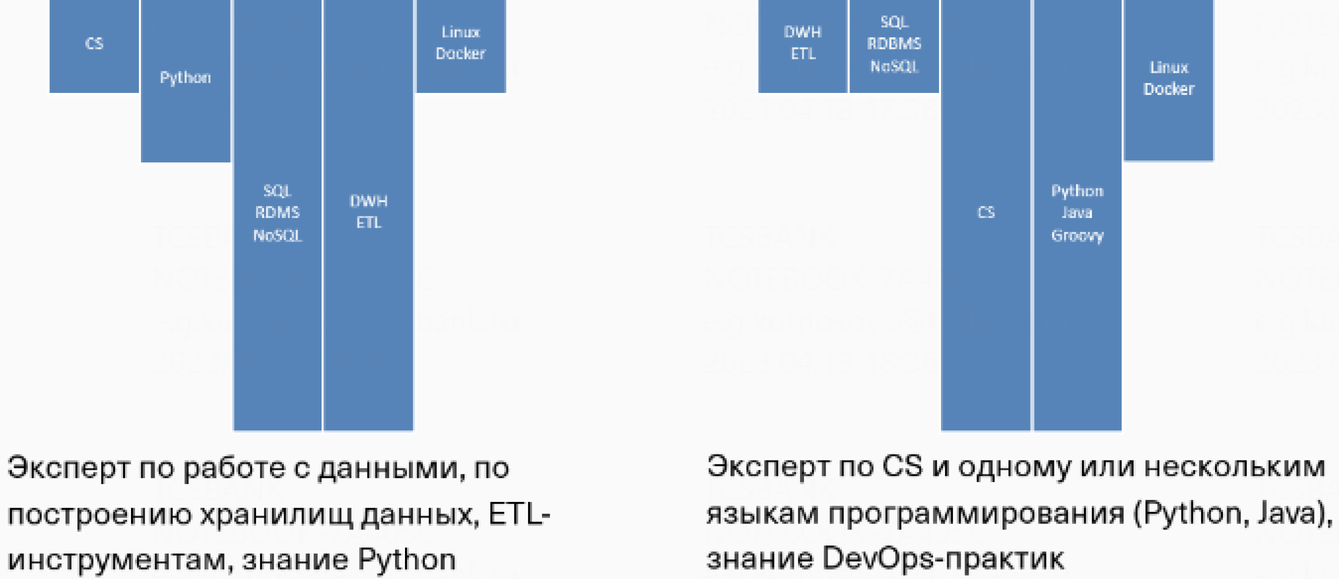
В матрице детально описаны требования, которые актуальны для data-инженеров разных профилей. Например:
- Java, Flink, Kafka, Cassandra и другие нужны для стриминговой обработки данных.
- Java, NiFi, Hadoop, Kafka, Redis и другие актуальны для core-команды, занимающейся развитием и эксплуатацией Apache NiFi.
- Python, Airflow, Greenplum, Clickhouse, Hadoop и другие необходимы для core-команды, занимающейся развитием batch ETL фреймворка на базе Apache Airflow.
Универсальность матрицы еще и в том, что в ней есть общие разделы. Они будут в той или иной степени полезны любому data-инженеру:
- основы хранилищ данных;
- SQL;
- теория СУБД, RDBMS, NoSQL, MPP;
- инженерные навыки;
- алгоритмы, структуры данных, сложность алгоритмов, паттерны проектирования.
Вся информация в матрице разделена по уровням компетенций — от junior до senior+. Это помогает понять, какие знания необходимы junior-специалисту, чтобы вырасти до мидла, а middle-специалисту — чтобы стать сеньором. За каждым data-инженером мы закрепляем ментора, который помогает составить индивидуальный план развития, опираясь на матрицу компетенций. Матрица помогает сотрудникам развиваться, но не определяет их уровень. Для этого у нас есть отдельная матрица уровней.
Периодически мы устраиваем аттестации — «экзамены» для data-инженеров. Любой желающий может сдать аттестацию на выбранный уровень, например middle. Благодаря матрице компетенций и механизму периодической оценки навыков мы можем быть уверены, что data-инженеры в наших командах могут быстро и гармонично развиваться.
Сейчас потребность в data-инженерах растет, потому что данные — это «новая нефть». А data-driven-подход требует умения работать с любыми данными, независимо от масштабов организации. Мы в Т‑Банке тоже приглашаем желающих присоединиться к нашей команде data-инженеров. Узнать подробности и посмотреть вакансии можно на нашей карьерной странице для data-инженеров.